为了加入学校里面一个技术小组,我接受了写一个爬取学校网站通知公告的任务。这个任务比以前写的爬虫更难的地方在于,需要模拟登录才能获得页面,以及将得到的数据存入数据库。
本文按照日期来记录我完成任务的过程,然后再整理一遍全部代码。读者可以通过侧栏目录跳转阅读。不介绍库的安装。
传送门:爬虫学习笔记 1
转载声明 关于参考链接: 本文用到的其他博客的链接都以(我自己对内容的概括或者文章原标题-来源网站-作者名)的格式给出,关于作者名,只有博客作者自己明确声明为“原创”,我才会加上作者名。引用的文章内容我会放在来源链接的下方。
关于本文: 我发一下链接都注明出处了,如果想转载,也请这样做。作者憧憬少 ,链接的话看浏览器地址栏。
任务介绍 爬取信息门户新闻并且存入数据库。
首先分解任务:
实现爬取综合新闻页面的公开新闻存入 markdown 文件中(190303 完成)
将数据存到数据库(190304 完成)
学习模拟登录(190305 到 190307 完成)
爬取信息门户新闻(190308 完成)
(进阶)将代码进行封装、优化(目前未封装)
(进阶)动态更新(目前未着手)
过程记录 190303 周日 练习爬取公开页面 我的第一个爬虫 是在 2 月多的时候在家写的,那个只是个简单的爬虫,目标是公开的页面,不需要模拟登录,也不需要存储到数据库,直接存到 txt 文件中。
先爬取学校官网的综合新闻页面复习一下。
首先讲一下我的思路:
由于新闻和公告页面通常是有一个目录页面的,也就是包含子页面的链接,在目录的子页面内才是正文内容。
假设这一页目录有三个新闻,就像是下面:
这样的结构。
如果要写一个爬虫函数来爬取所有新闻页面,那么就要从目录着手。目录中含有前往别的新闻页面的链接,所以可以在目录页获取本页所有新闻的链接,遍历所有链接并提取新闻内容。
至于翻页也可以这样做到,“下一页”按钮也是一个链接,可以通过这个链接获取到下一页的内容。翻页部分原理比较简单,我是先攻克其他难关,把它留到最后写的。
提取单页面新闻 首先是提取单个页面的新闻。向目标 url 发出访问请求:
1 2 3 4 5 6 7 8 9 10 11 import requestsdef getNews (url ): ''' 提取页面的新闻与图片并存储为markdown文件 :param url: 要爬取的目标网页url :return: 无 ''' r=requests.get(url) html=r.text print(html)
编码问题 这里遇到了第一个问题,提取到的页面有乱码。
解决方法:先获取响应对象的二进制响应内容,然后将其编码为 utf8
参考链接:
requests.content 返回的是二进制响应内容
而 requests.text 则是根据网页的响应来猜测编码
字符串在 Python 内部的表示是 unicode 编码,在做编码转换时,通常需要以 unicode 作为中间编码,即先将其他编码的字符串解码(decode)成 unicode,再从 unicode 编码(encode)成另一种编码。
decode 的作用是将其他编码的字符串转换成 unicode 编码,如 str1.decode(‘gb2312’),表示将 gb2312 编码的字符串 str1 转换成 unicode 编码。
encode 的作用是将 unicode 编码转换成其他编码的字符串,如 str2.encode(‘utf-8’),表示将 unicode 编码的字符串 str2 转换成 utf-8 编码。
修改代码为:
1 2 3 4 r=requests.get(url) html=r.content html=html.decode('utf-8' )
解析网页(bs4) 一开始我和之前一样使用正则表达式来提取,但是不够熟悉,总是写不出匹配的上的正则表达式。还是使用另一个东西——BeautifulSoup 库
具体如何使用请查看其他教程,本文只说我自己用到的部分。
参考链接:
BeautifulSoup 是 Python 的一个库,最主要的功能就是从网页爬取我们需要的数据。BeautifulSoup 将 html 解析为对象进行处理,全部页面转变为字典或者数组,相对于正则表达式的方式,可以大大简化处理过程。
我目前的理解是,这个 BeautifulSoup 库需要用到其他 html 解析库,可以使用 python 自带的,也可以安装第三方库,其他的库就像功能扩展插件一样,没有的话它自己也能解析。我安装了名为 lxml 的解析库。
查看源代码,找到网页中有关新闻的代码,手动将其格式化之后如下(内容不重要,省略):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 <h1 class ="arti-title" > 标题省略</h1 > <p class ="arti-metas" > <span class ="arti-update" > 发布时间:2019-01-23</span > <span class ="arti-update1" > 作者:xx</span > <span class ="arti-update2" > 来源:xxx</span > </p > <div class ="entry" > <article class ="read" > <div id ="content" > <div class ="wp_articlecontent" > <p > 新闻前言省略</p > <p > <br /> </p > <p > 新闻内容省略</p > <p > <img width ="556" height ="320" align ="bottom" src ="url省略" border ="0" /> </p > <p style ="text-align:right;" > (审稿:xx 网络编辑:xx)</p > </div > </div > </article > </div >
接着上面的代码:
1 2 3 4 5 6 7 8 9 soup=BeautifulSoup(html,"lxml" ) title=soup.find('h1' ,class_='arti-title' ).string update=soup.find('span' ,class_='arti-update' ).string content=soup.find('div' ,class_='wp_articlecontent' )
提取图片 我打算将新闻保存到 markdown 文件中,提取新闻中的图片的链接的地址,这样在 md 文件中就能显示出图片了。
1 2 3 4 5 6 7 base='学校官网url,用于和img标签中的相对地址拼接成绝对地址' imgsTag=content.find_all('img' ) imgsUrl=[] for img in imgsTag: imgsUrl.append(base+img['src' ]) img.extract()
删除多余标签 1 2 3 4 5 6 for p in content.find_all('p' ,{'style' :"text-align:center;" }): p.extract() p=content.find('p' , {'style' : "text-align:right;" }) if (p!=None ): p.extract()
保存到文件 1 2 3 4 5 6 7 8 9 10 11 12 fileContent='' for i in content.contents: if (i.string!=None ): fileContent+=i.string fileContent+='\n\n' with open('data.md' ,'w' ) as fout: fout.write(fileContent)
代码总览 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 import requestsfrom bs4 import BeautifulSoupdef getNews (url ): ''' 提取页面的新闻与图片并存储为markdown文件 :param url: 要爬取的目标网页url :return: 无 ''' r=requests.get(url) html=r.content html=html.decode('utf-8' ) soup=BeautifulSoup(html,"lxml" ) content=soup.article title=soup.find('h1' ,class_='arti-title' ).string update=soup.find('span' ,class_='arti-update' ).string content=soup.find('div' ,class_='wp_articlecontent' ) base='http://xxxxx.xxx' imgsTag=content.find_all('img' ) imgsUrl=[] for img in imgsTag: imgsUrl.append(base+img['src' ]) img.extract() for p in content.find_all('p' ,{'style' :"text-align:center;" }): p.extract() p=content.find('p' , {'style' : "text-align:right;" }) if (p!=None ): p.extract() fileContent='' for i in content.contents: if (i.string!=None ): fileContent+=i.string fileContent+='\n\n' with open('data.md' ,'w' ) as fout: fout.write(fileContent)
提取多页面新闻 原理在上面说了,提取完单页基本上就完成了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import requestsfrom bs4 import BeautifulSoupdef getNewsContents (url ): ''' 爬取目录页面链接到的页面 :param url: 新闻目录页面的url :return: 无 ''' r=requests.get(url) html=r.content html=html.decode('utf-8' ) base='http://xxxxx.xxx' soup=BeautifulSoup(html,'lxml' ) for page_url in soup.find_all('a' ,class_='column-news-item' ): page_url=base+'/' +page_url['href' ] print(page_url) getNews(page_url)
day1 进度
实现爬取长安大学综合新闻页面的公开新闻存入 markdown 文件中
复习了 requests 库的使用
学习了 BeautifulSoup4 库的基本使用
190304 周一 这一天主要是将前一天爬取的数据存入数据库。
将数据存入数据库 安装 MySQL 数据库 参考链接:
使用 MySQL Workbench MySQL Workbench 是一个可视化工具,安装 MySQL 的时候自带(我安装的是最新版的),在安装目录找到它的 exe 然后加个快捷方式在桌面,可以方便地查看数据和执行 SQL 查询指令,具体使用方法可以问度娘。我现在也不是很会。
我创建的数据库名为 news,里面创建了一个数据表 chdnews。
连接数据库 和大多数数据库一样,MySQL 是 C/S 模式的,也就是客户端(client)/服务端(server)模式的。数据库有可能在远程服务器上。想要使用数据库,就需要连接到数据库。
python 中要使用数据库需要一个 pymysql 库。
下面是连接的代码:
1 2 3 import pymysqldb = pymysql.connect(host='127.0.0.1' , port=3306 , user='root' , passwd='root' , db='news' , charset='utf8' )
这个连接函数看参数名就可以看出含义了。
host:主机 ip,127.0.0.1 是回传地址,指本机。也就是连接本电脑的 MySQL 的意思
port:端口号,用来和 ip 一起指定需要使用数据库的软件。在安装的时候会让你设置,默认 3306
user&passwd:用户名和密码,在安装的时候已经设置好了
db:你要连接的数据库的名字。一台电脑上可以有很多数据库,数据库里面可以有很多数据表。
charset:字符编码
插入数据 接着可以准备一个游标,游标大概是一个用于存储结果集开头地址的指针吧,我是这么理解的。在我学了更多数据库知识后可能会更新这一部分。
接着执行 SQL 的插入语句:
1 2 cursor.execute("insert into chdnews(`title`,`article`) values('{0}','{1}')" .format(title,fileContent))
这里的 SQL 语句是这样的:
1 insert into 数据表名(字段名1 ,字段名2 ) values (值1 ,值2 )
后面的format函数是 python 的格式化函数,将变量的值加入到字符串中对应位置。
最后提交:
接着打开 workbench,就会发现已经存入数据库了。(你得把代码放在上面提取单页新闻的函数那里,放在保存到文件的那部分代码那儿)
day2 进度
下载并安装 MySQL 以及 MySQL Workbench
使用 pymysql 库进行数据库的连接,实现了把第一天得到的数据存入数据库
190305 周二 初步了解模拟登录 最后的任务需要爬取登录后才能查看的页面,于是我去搜索了很多博客,只放一部分对我有帮助的链接。
参考链接:
首先查看一下需要的登录数据:
打开登录网页,用 F12 打开开发者工具,选择 network(网络)选项卡
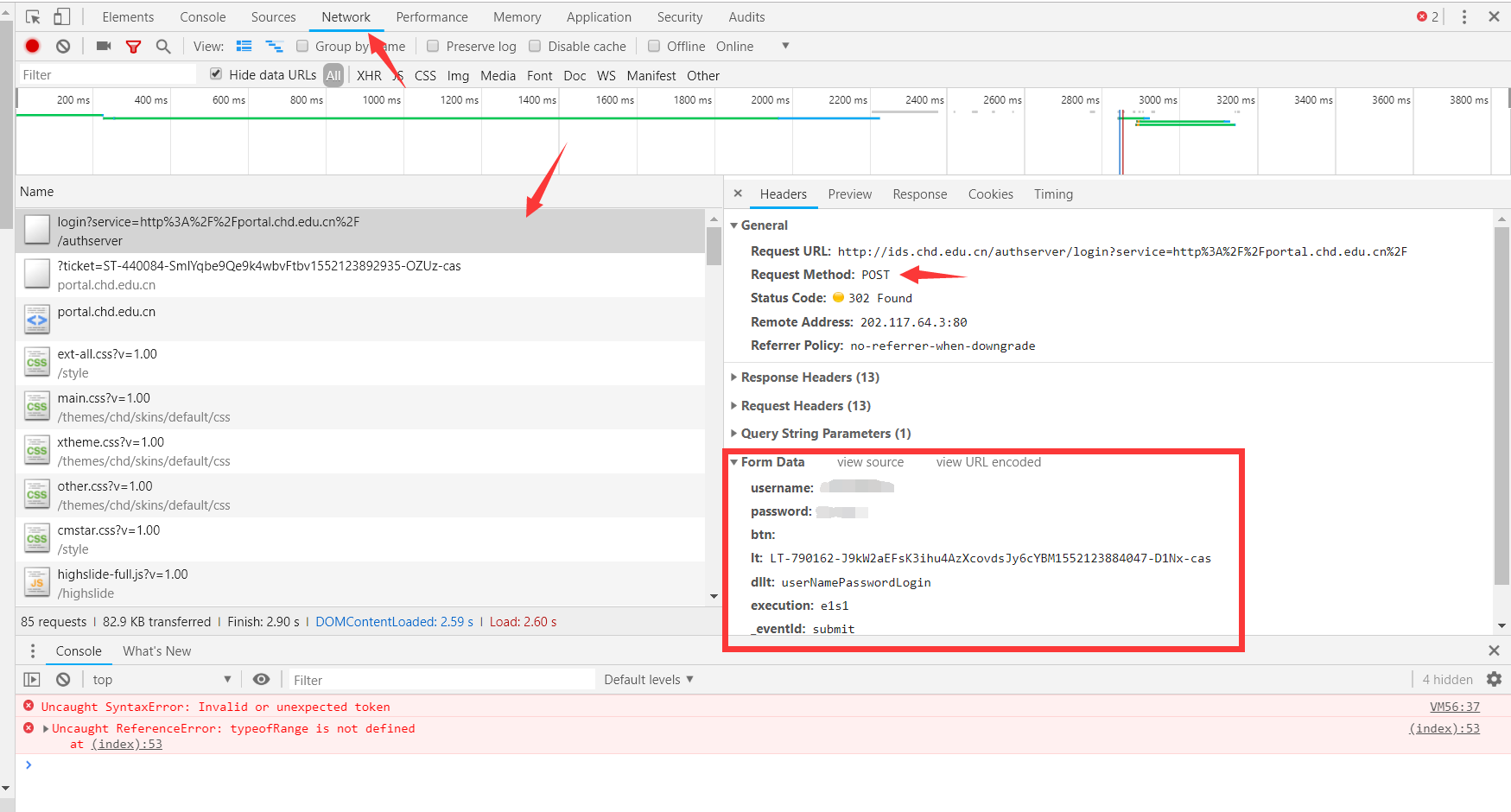
登录你的账号,此时控制台会显示一大堆请求与响应,找到以 post 方式发送的请求,一般排在第一个
那里会显示几个栏目,找到Form Data(表单数据),这个里面是你填写登录表单之后使用 POST 方式发送给服务端的内容。这里面除了自己填写的账号密码之外还有一些东西,比如下图的lt,dllt,execution,_eventId,rmShown这些都是在表单的隐藏域中,查看登录页面的源代码是可以看的到的。这些隐藏起来的东西是为了检验你是否是从浏览器进来的,只要获取到这些东西,再加上头部信息,就能伪装成浏览器了
至于头部信息,在下图也可以看到我折叠起来的几个栏目,有一个是Request Headers,这是我们在点击登录按钮时发送的 POST 请求信息的信息头。将里面的User-Agent给复制到你代码里面存在一个字典里面等会用
把头部信息和表单数据都看一下,准备一下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 login_url = 'http://xxxx.xxx' headers={ 'User-Agent' :'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36' 'Host' :'xx.xx.xx.xx' , 'Referer' :'http://xxx.xxx?xxx=http://xxx.xx' , 'Origin' :'http://xxx.xxx.xx' } login_data={ 'username' : '你的账号' , 'password' : '你的密码' , 'btn' :'' , 'lt' : LT-790162 -J9kW2aEFsK3ihu4AzXcovdsJy6cYBM1552123884047-D1Nx-cas, 'dllt' : 'userNamePasswordLogin' , 'execution' : 'e1s1' , '_eventId' : 'submit' , 'rmShown' : 1 }
数据准备好之后就开始登录,使用的是 requests 的另一个方法——post。
向服务器发出请求(request)的方式有 get 和 post,查看 html 源代码的时候在表单标签处可以看到表单提交的方法。如:
1 <form id ="casLoginForm" method ="post" > </form >
像这样写 html 代码会让浏览器在你按下登录按钮的时候以 post 的方式提交表单,也就是以 post 的方式向服务器发起 request,将 form data 发送过去。
post 方法的好处是在发送过程中会隐藏你的表单数据,不会被直接看到;
而前面使用过的 get 方法,会把你的表单数据加在 url 后面,网址后边以问号开头,以&连接的就是发送过去的参数。
涉及登录用 post 比较好,以免轻易泄露密码。
1 2 r=requests.post(login_url,headers=headers,data=login_data)
按理来说应该可以了呀,为什么不行?仍然得到登录页面。在这一天我折腾了很久,没有得到答案。
不过在找资料时却学到了其他的一些知识,关于 cookie 和 session。
cookie 和 session 我目前的理解(如果不对欢迎留言):
http 是无状态协议,两次访问都是独立的,不会保存状态信息。也就是你来过一次,下次再来的时候网站还是当你第一次来。那么怎么知道你来过,从而给你还原之前的数据呢?就有人想出 cookie 和 session 两种方式。
cookie (直译:小甜饼)是服务端(网站服务器)收到客户端(你电脑)的 request(请求)的时候和 response(响应)一起发给客户端的数据。客户端把它存在文件里面,并在下一次访问这个网站时将 cookie 随着 request 一起发送过去,这样服务端就会知道你就是之前来过的那个人了。cookie 存储在客户端。
客户端发送 request
服务端发送 response 附带一个 cookie(一串数据)
客户端第二次访问时把 cookie 复制一份一起发过去
服务端看到你的 cookie 就知道你是谁了
session (会话)是在服务端内存中保存的一个数据结构,一旦有客户端来访问,那么就给这个客户端创建一个新的 session 在服务端的内存,并将它的 session ID 随着 response 发回给客户端。客户端第二次访问时,会将被分配的 SID 随着 request 一起发过来,服务端在这边验证 SID 之后就会知道你来过。session 存储在服务端。
客户端发送 request
服务端发送 response 并在自己这边创建一个 session(一堆数据)并发送一个 session ID 给客户端
客户端第二次访问时把 session ID 一起发过去
服务端看到你的 session ID 就知道你是谁了
不过这俩是用来保持登录的,我还没登录成功想这个干啥?请看下一天。
day3 进度
初步了解 cookie 和 session 的概念
了解如何使用 chrome 浏览器的控制台查看 post 表单信息
尝试使用 requests 的 post 方法模拟登录,失败,返回登录页面
190306 周三 表单校验码(非验证码) 怎么弄都不成功,都跳回登录页面。我只好去询问组长这是为什么。
原来我没发现表单校验码会变的!
一直没注意啊啊啊啊啊啊!
我没有认真比对过两次打开的乱码不一样,看结尾一样就以为一样了。其中的lt这个域每次打开网页都是不一样的,随机出的!
既然知道了问题,就好解决了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 html=requests.post(login_url,headers=headers).text soup=BeautifulSoup(html,'lxml' ) lt=soup.find('input' ,{'name' :'lt' })['value' ] dllt=soup.find('input' ,{'name' :'dllt' })['value' ] execution = soup.find('input' , {'name' : 'execution' })['value' ] _eventId = soup.find('input' , {'name' : '_eventId' })['value' ] rmShown = soup.find('input' , {'name' : 'rmShown' })['value' ] login_data={ 'username' : input("请输入学号:" ), 'password' : input("请输入密码:" ), 'btn' :'' , 'lt' : lt, 'dllt' : dllt, 'execution' : execution, '_eventId' : _eventId, 'rmShown' : rmShown }
为了保险,我把其他的表单域也给解析赋值给变量了。
不过仍然无法登陆成功,而是进入了一个诡异的页面:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 <!DOCTYPE html > <html > <head > <title > Welcome to nginx!</title > <style > body { width: 35em; margin: 0 auto; font-family: Tahoma, Verdana, Arial, sans-serif; } </style > </head > <body > <h1 > Welcome to nginx!</h1 > <p > If you see this page, the nginx web server is successfully installed and working. Further configuration is required. </p > <p > For online documentation and support please refer to <a href ="http://nginx.org/" > nginx.org</a > .<br /> Commercial support is available at <a href ="http://nginx.com/" > nginx.com</a > . </p > <p > <em > Thank you for using nginx.</em > </p > </body > </html >
确实有进展,但是这是啥?nginx?查了一下是一个高性能的 HTTP 和反向代理服务器,但是和我现在登录有什么关系呢?(黑人问号.jpg)
利用 session 保持校验码 即使登录成功,还有一个问题无法解决,那就是我获取校验码的 request 和登录用的 request 是两次不同的访问请求呀,这样校验码又会变化。
我想起了前一天看到的 session,这玩意不就能让服务端记住我?(cookie 试了一下,保存下来的是空的文件不知道怎么回事)
于是新建一个会话:
1 2 session=requests.session()
在获取校验码的时候改成使用 session 变量来发起请求:
1 2 html=session.post(login_url,headers=headers).text
这里的 session 是在客户端创建的,并不是服务端那个,我想它可能存储的是服务端发送过来的 session ID 吧。
同理在正式发送请求时这样:
1 2 r=session.post(login_url,headers=headers,data=login_data)
这样就能让服务端知道我是刚刚获取校验码的那个小伙汁:D
在这一天我没有办法验证是否有效,不过在之后我验证了这个方法的成功性。
day4 进度
知道了原来有个每次会变化的校验码“lt”,找到了跳转回登录页面的原因。使用 Beautifulsoup 来获取每次的校验码,不过仍然没有解决无法登录的问题
使用 session 对象来保证获取校验码和登录时是同一个会话,未验证
190307 周四 多余的头部信息 我终于发现了问题所在!!!!!
1 2 3 4 5 6 7 headers={ 'User-Agent' :'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36' , }
头部信息写多了,我只保留了User-Agent之后成功登录了,你们能体会到我当时有多开心吗!
我将成为新世界的卡密小组里面最快完成的人!
解决了这个问题,剩下的就特别简单了。
当时我有一个下午的时间,于是我将进度迅速推进。
爬取通知公告 设登录页面为 pageA,登录之后的页面跳转到 pageB,而 pageB 有一个按钮跳转到 pageC,这个 pageC 就是 day1 的时候的目录页面,里面有着 pageC1、pageC2、pageC3……等页面的链接,而这个 pageC 最后面还有个按钮用于跳转到目录的下一页,也就是 pageC?pageIndex=2,还有 137 页公告栏目录。
没有什么新的东西,和 day1 说的爬取方式差不多,只是页面正文的格式和 day1 的新闻不太一样。核心结构如下,我省略了很多:
1 2 3 4 5 6 7 8 9 10 11 12 13 <html > <body > <div class ="bulletin-content" id ="bulletin-contentpe65" > <p style =";background: white" > <a name ="_GoBack" > </a > <span style ="font-size: 20px;font-family: 仿宋" > 校属各单位: </span > </p > <p > <br /> </p > </div > </body > </html >
大概就是一个<p>标签里面放一个或多个<span>标签,而这里面可能还会嵌套几个<span>标签,里面才有内容,而两个内部的<span>之间还可能有内容。
这要怎么解析?
在尝试了很多方案之后,我终于百度到一个函数:
参考链接:
解决方案:
1 2 3 4 5 6 7 8 9 10 html=session.post(url,headers=headers).text soup=BeautifulSoup(html,'lxml' ) article=soup.find('div' ,class_='bulletin-content' ) news_content='' for p in article.find_all('p' ): if p.span!=None : text=str(p.get_text()).strip() news_content+=text+'\n'
接着我就把爬下来的东西存到数据库里面去了。弄完之后得去赶作业了,这一天的时间用完了。
day5 进度 1.找到无法登录且跳转到未知页面的原因是头部信息加了多余的值,解决之后成功登录到信息门户,实现模拟登陆 2.利用之前爬取单个页面到文件的方法,用 beautifulsoup 解析并保存内容到文件 3.存入 MySQL 数据库中 4.还差爬取多页目录的功能,预计明天完成。整理代码后可提交
190308 周五 更多的目录页 开了一个新文件准备整理一下代码,并完成最后一个功能——爬取完目录页第一页之后爬取后面更多的页。
查看源代码的时候,找“第二页”这个按钮对应的链接,发现了规律:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 <div class ="pagination-info clearFix" > <span title ="共2740条记录 分137页显示" > 2740/137 </span > <a href ="detach.portal?pageIndex=1& pageSize=& .pmn=view& .ia=false& action=bulletinsMoreView& search=true& groupid=all& .pen=pe65" title ="点击跳转到第1页" > < < </a > <div title ="当前页" > 1</div > <a href ="detach.portal?pageIndex=2& pageSize=& .pmn=view& .ia=false& action=bulletinsMoreView& search=true& groupid=all& .pen=pe65" title ="点击跳转到第2页" > 2</a > <a href ="detach.portal?pageIndex=3& pageSize=& .pmn=view& .ia=false& action=bulletinsMoreView& search=true& groupid=all& .pen=pe65" title ="点击跳转到第3页" > 3</a > <a href ="detach.portal?pageIndex=4& pageSize=& .pmn=view& .ia=false& action=bulletinsMoreView& search=true& groupid=all& .pen=pe65" title ="点击跳转到第4页" > 4</a > <a href ="detach.portal?pageIndex=5& pageSize=& .pmn=view& .ia=false& action=bulletinsMoreView& search=true& groupid=all& .pen=pe65" title ="点击跳转到第5页" > 5</a > <a href ="detach.portal?pageIndex=6& pageSize=& .pmn=view& .ia=false& action=bulletinsMoreView& search=true& groupid=all& .pen=pe65" > > </a > <a href ="detach.portal?pageIndex=137& pageSize=& .pmn=view& .ia=false& action=bulletinsMoreView& search=true& groupid=all& .pen=pe65" title ="点击跳转到最后页" > > > </a > </div >
可以看出,指向其他目录页的相对链接,只是参数略有不同,参数中只有pageIndex发生了变化。至于给 url 加参数,我记得前几天看到过。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 para={ 'pageIndex' :1 , 'pageSize' :'' , '.pmn' :'view' , '.ia' :'false' , 'action' :'bulletinsMoreView' , 'search' :'true' , 'groupid' :'all' , '.pen' :'pe65' } catalogue_url='http://xxx.xx.xx.cn/detach.portal' session = login() for i in range(1 ,page_count+1 ): para['pageIndex' ]=i html = session.post(catalogue_url,params=para).text
整理代码 要用到的库
1 2 3 4 import requestsimport refrom bs4 import BeautifulSoupimport pymysql
get_bulletin 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 def get_bulletin (page_count ): ''' 目录有多页,从第一页开始获取,往后获取page_count页的目录,并读取目录指向的所有公告 :param page_count: 要爬取的目录页面的数量 :return: 无 ''' para={ 'pageIndex' :1 , 'pageSize' :'' , '.pmn' :'view' , '.ia' :'false' , 'action' :'bulletinsMoreView' , 'search' :'true' , 'groupid' :'all' , '.pen' :'pe65' } catalogue_url='http://xxx.xxx.xxx.cn/detach.portal' session = login() for i in range(1 ,page_count+1 ): para['pageIndex' ]=i html = session.post(catalogue_url,params=para).text soup = BeautifulSoup(html, 'lxml' ) rss_title = soup.find_all('a' , class_='rss-title' ) bulletin_dict = {} for url in rss_title: bulletin_title = str(url.span.string).strip() bulletin_url = 'http://xxx.xx.xx.cn/' + url['href' ] bulletin_dict.setdefault(bulletin_title, bulletin_url) for bulletin_title, bulletin_url in bulletin_dict.items(): saveInDB(news_url, session, news_title)
login 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 def login (): """ 登录并返回已经登录的会话 :return: 已经登录的会话(session) """ login_url = 'http://xxx.xx.xx.cn/authserver/login?service=http%3A%2F%2F%2F' headers={ 'User-Agent' :'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36' } session=requests.session() html=session.post(login_url,headers=headers).text soup=BeautifulSoup(html,'lxml' ) lt=soup.find('input' ,{'name' :'lt' })['value' ] dllt=soup.find('input' ,{'name' :'dllt' })['value' ] execution = soup.find('input' , {'name' : 'execution' })['value' ] _eventId = soup.find('input' , {'name' : '_eventId' })['value' ] rmShown = soup.find('input' , {'name' : 'rmShown' })['value' ] login_data={ 'username' : input("请输入学号:" ), 'password' : input("请输入密码:" ), 'btn' :'' , 'lt' : lt, 'dllt' : dllt, 'execution' : execution, '_eventId' : _eventId, 'rmShown' : rmShown } response=session.post(login_url,headers=headers,data=login_data) if response.url=='http://xxx.xx.xx.cn/' : print('登录成功!' ) return session
saveInTXT 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 def saveInTXT (url, session, title ): ''' 获取单个公告页面的公告并保存到txt :param url: 要获取的页面的url :param session:已经登录的会话 :param title:公告标题 :return:无 ''' reg = r'[\/:*?"<>|]' title = re.sub(reg, "" , title) path='bullet\\' + title+'.txt' headers = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36' } ''' #测试代码,从文件读取手动获取的公告html页面,单机测试 with open('new.txt','r',encoding='utf8') as fin: html=fin.read() ''' html=session.post(url,headers=headers).text soup=BeautifulSoup(html,'lxml' ) bulletin_content=soup.find('div' , class_='bulletin-content' ) bulletin_content= '' for p in bulletin_content.find_all('p' ): if p.span!=None : text=str(p.get_text()).strip() bulletin_content+= text + '\n' with open(path,'w' ,encoding='utf8' ) as fout: fout.write(bulletin_content) print('“{}”成功保存到{}' .format(title,path))
saveInDB 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 def saveInDB (url, session, title ): ''' 获取单个公告页面的公告并保存到txt :param url: 要获取的页面的url :param session:已经登录的会话 :param title:公告标题 :return:无 ''' headers = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36' } html=session.post(url,headers=headers).text soup=BeautifulSoup(html,'lxml' ) bulletin_content=soup.find('div' , class_='bulletin-content' ) bulletin_content= '' for p in bulletin_content.find_all('p' ): if p.span!=None : text=str(p.get_text()).strip() bulletin_content+= text + '\n' db = pymysql.connect(host='127.0.0.1' , port=3306 , user='root' , passwd='root' , db='news' , charset='utf8' ) cursor = db.cursor() cursor.execute("insert into chdnews(`title`,`content`) values('{0}','{1}')" .format(title, bulletin_content)) db.commit() print('已经成功保存公告到数据库:“{}”' .format(title))
调用 暂时没有将其通用化,直接将网址写死在函数里面了。
day6 进度
通过调整服务门户的 url 中的参数来获取通知公告的每一个目录页的 url,从而爬取所有公告
将学习中写的测试代码重新构造整理,添加函数注释,提交任务
190309 周六 day7 进度 写了本篇博客进行总结