将登陆学校信息门户的部分专门封装成一个模块,需要的时候导入。
相关链接
本文代码的 github 链接
获取登录所需表单数据
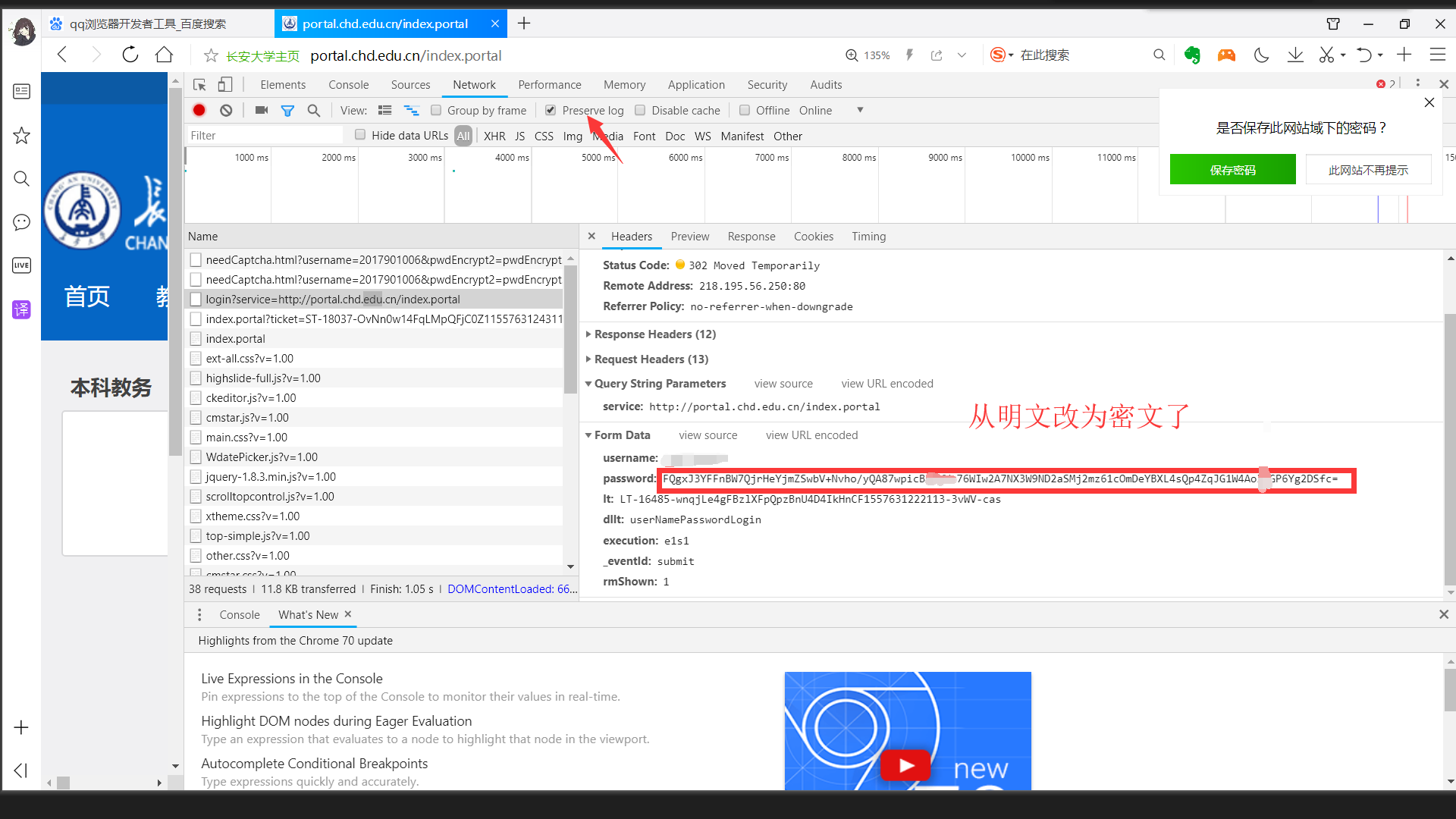
从图中看到的,和在登录页面源代码中查找的,需要的表单数据如下:
- username:用户名,也就是信息门户账号
- password:是经过加密之后的密码
- lt:是一个每次请求都会变化的表单隐藏域值
- dllt:固定表单隐藏域值
- execution:固定表单隐藏域值
- _eventId:固定表单隐藏域值
- rmShown:固定表单隐藏域值
除了需要表单数据之外,还需要在登录页面源代码中获取密钥,详情见:学校信息门户模拟登录之密码加密
使用BeautifulSoup来获取这些数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| from portal_login.encrypt import *
import requests
from bs4 import BeautifulSoup
def get_login_data(login_url,headers):
'''
长安大学登录表单数据解析
:param login_url: 登录页面的url
:return (登录信息字典,获取时得到的cookies)
'''
username=input('input username:')
password=input('input password:')
username.strip()
password.strip()
response=requests.get(login_url,headers=headers)
html=response.text
soup=BeautifulSoup(html,'lxml')
pattern = re.compile('var\s*?pwdDefaultEncryptSalt\s*?=\s*?"(.*?)"')
key = pattern.findall(html)[0]
password=encrypt_aes(password,key)
lt=soup.find('input',{'name':'lt'})['value']
dllt=soup.find('input',{'name':'dllt'})['value']
execution = soup.find('input', {'name': 'execution'})['value']
_eventId = soup.find('input', {'name': '_eventId'})['value']
rmShown = soup.find('input', {'name': 'rmShown'})['value']
login_data={
'username': username,
'password': password,
'lt': lt,
'dllt': dllt,
'execution': execution,
'_eventId': _eventId,
'rmShown': rmShown
}
return (login_data,response.cookies)
|
要注意的是,获取完数据之后,需要将 response 的 cookies 留下来,因为不同 cookies 对应的登录数据也不一样(比如说每次打开页面都不一样的密钥和 lt)
登录
登录过程分析
在登录页面输入账号密码,F12 打开开发者工具,Network勾选Preserve log,点击登录,然后就会出现下图场景:
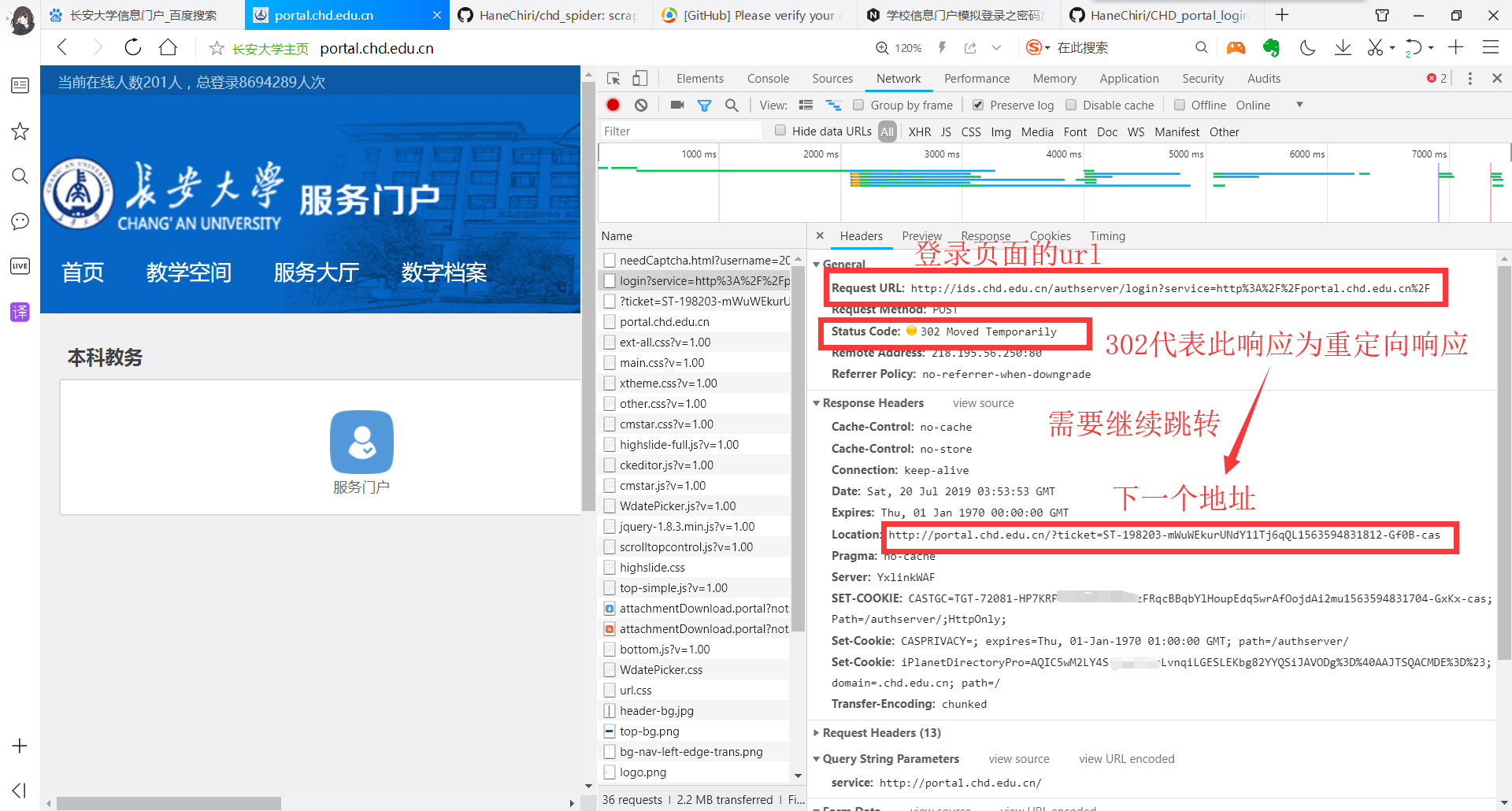
找到从登陆页面出去的第一个响应,可以发现这个响应的状态码是 302,代表“重定向”。在Response Headers里面可以找到Location这个键,它指示的是重定向的地址。
这个响应的含义大概是“服务器告诉浏览器带着给它的 cookies 去访问Location指示的 url”
在刷出来的一大堆响应中继续寻找,找到下一个地址:
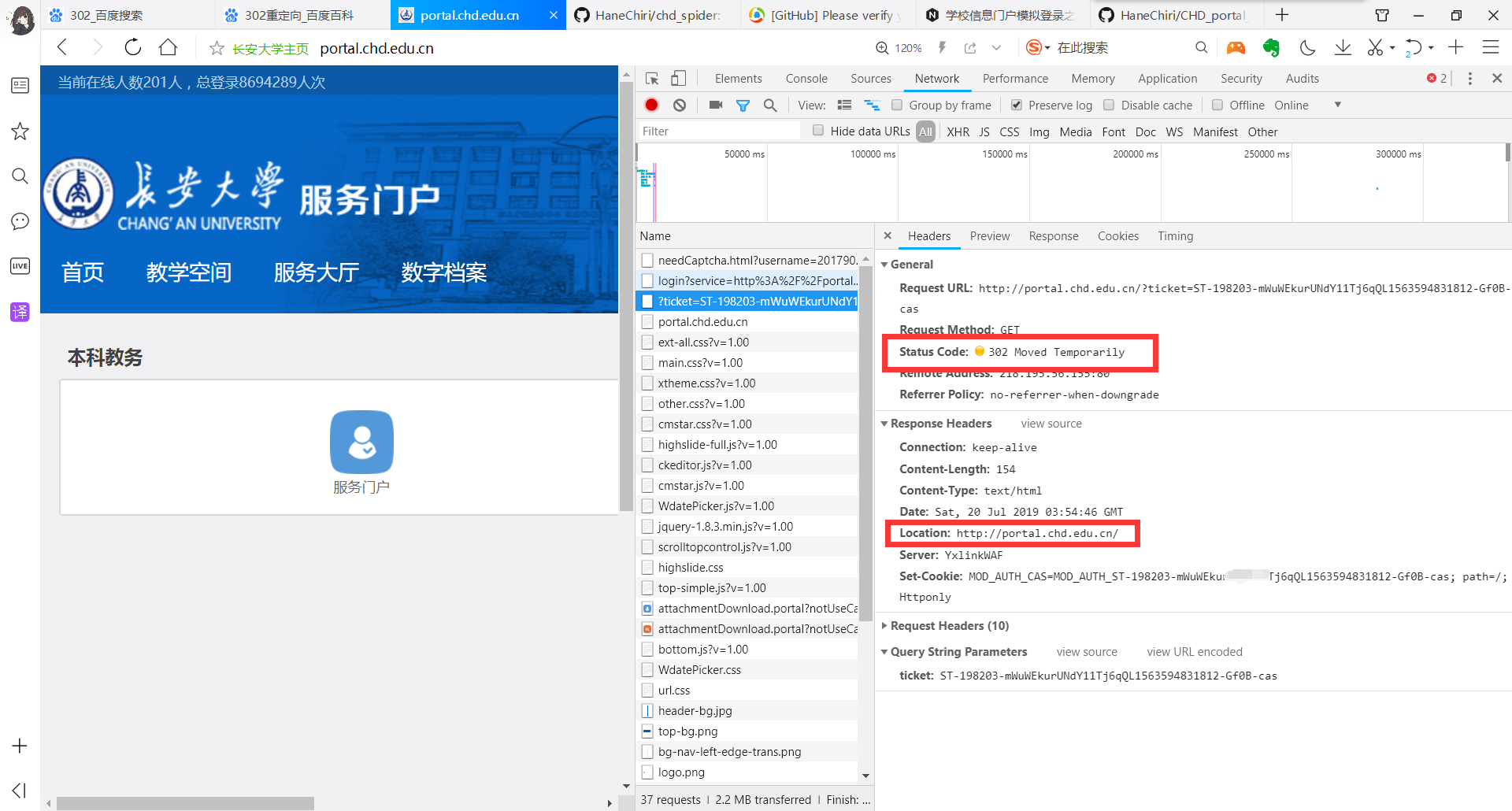
从图中可以看到,目的地址已经是门户的主页 url 了,继续跳转:
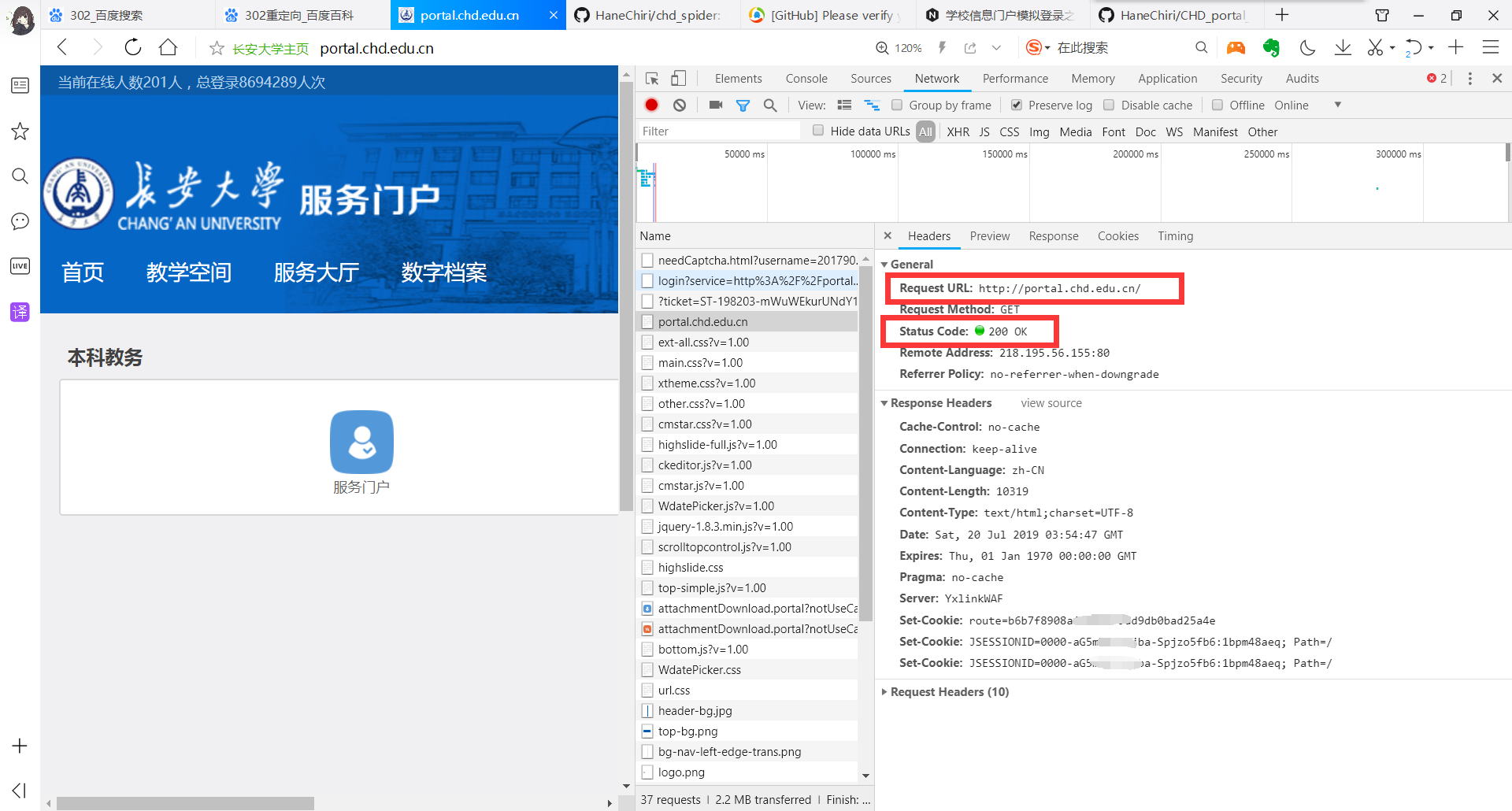
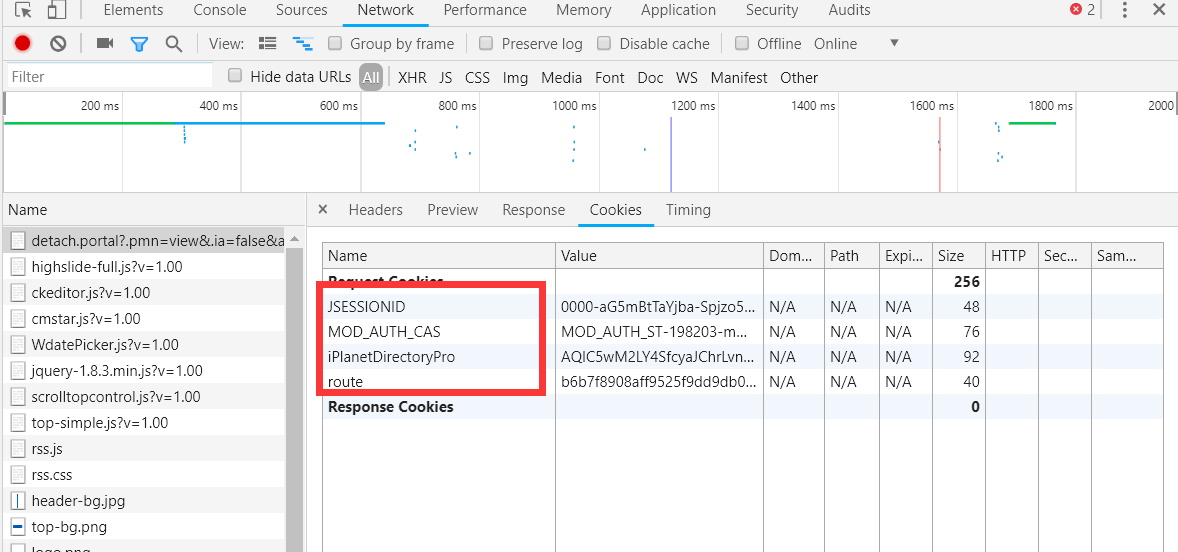
随便打开一个登陆才能查看的页面,查看它的 cookie,发现浏览器带着这几个 cookies 来访问这个页面,也就是说,我们需要获取到这几个 cookies,才能登录成功:
处理跳转
默认情况下,requests 的post()方法是得到跳转后最终页面的响应,也就是说,登录成功就返回门户主页的响应,登录失败就返回跳转之后回到的登录页面的响应。
需要设置一个参数,来阻止它进行跳转:
1
| response=requests.post(login_url,headers=headers,data=data,cookies=cookies,allow_redirects=False)
|
也就是:
不允许跳转,第一次请求得到什么响应就返回什么响应。
每一次跳转,我们需要做的工作如下:
- 将现有的 cookies 与新获取的 cookies 合并
- 找到下一个重定向地址,带上 cookies,再一次请求
实现代码如下:
1
2
3
4
5
6
7
8
9
| response=requests.post(login_url,headers=headers,data=data,cookies=cookies,allow_redirects=False)
while response.status_code == 302:
cookies=join_cookies(cookies,response.cookies)
next_station=response.headers['Location']
response=requests.post(next_station,headers=headers,cookies=cookies,allow_redirects=False)
cookies=join_cookies(cookies,response.cookies)
|
其中join_cookies()的实现如下:
1
2
3
4
5
6
7
| def join_cookies(cookies1,cookies2):
'''
将cookies1和cookies2合并
'''
cookies=dict(cookies1,**cookies2)
cookies=requests.utils.cookiejar_from_dict(cookies)
return cookies
|
登录函数总览
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| def login(login_url,headers,check_url=None):
'''
登录到CHD信息门户
:param login_url: 登录页面的url
:param headers: 使用的headers
:param check_url: 用于检查的url,尝试请求此页面并核对是否能请求到
:return: 已登录的cookies
'''
data,cookies=get_login_data(login_url,headers)
response=requests.post(login_url,headers=headers,data=data,cookies=cookies,allow_redirects=False)
while response.status_code == 302:
cookies=join_cookies(cookies,response.cookies)
next_station=response.headers['Location']
response=requests.post(next_station,headers=headers,cookies=cookies,allow_redirects=False)
cookies=join_cookies(cookies,response.cookies)
if check_url != None:
response = requests.get(check_url,headers=headers,cookies=cookies)
if response.url==check_url:
print("登录成功")
else:
print("登录失败")
return cookies
|