智能信息检索这门课程有个上机作业,题目是“实现倒排索引”。
用到了以前没有学的 STL 中的 vector。
经过两次课上写代码(3 小时)加上课后修 bug 的时间(晚上十点到十二点)总共 5 个小时,终于完成了一个简易的倒排索引。因为十点时已经太困,喝了柠檬茶提神结果现在睡不着,所以继续熬夜把博客写完吧。
前言 勿抄袭代码,代码仅供参考。转载注明出处
倒排索引简介 为了从文档集(collection)中检索出想要的结果,首先要将文档集中的每个词项(term)建立索引,以确定词项所在的文档(document)的 id,从而返回根据关键字查询的结果。
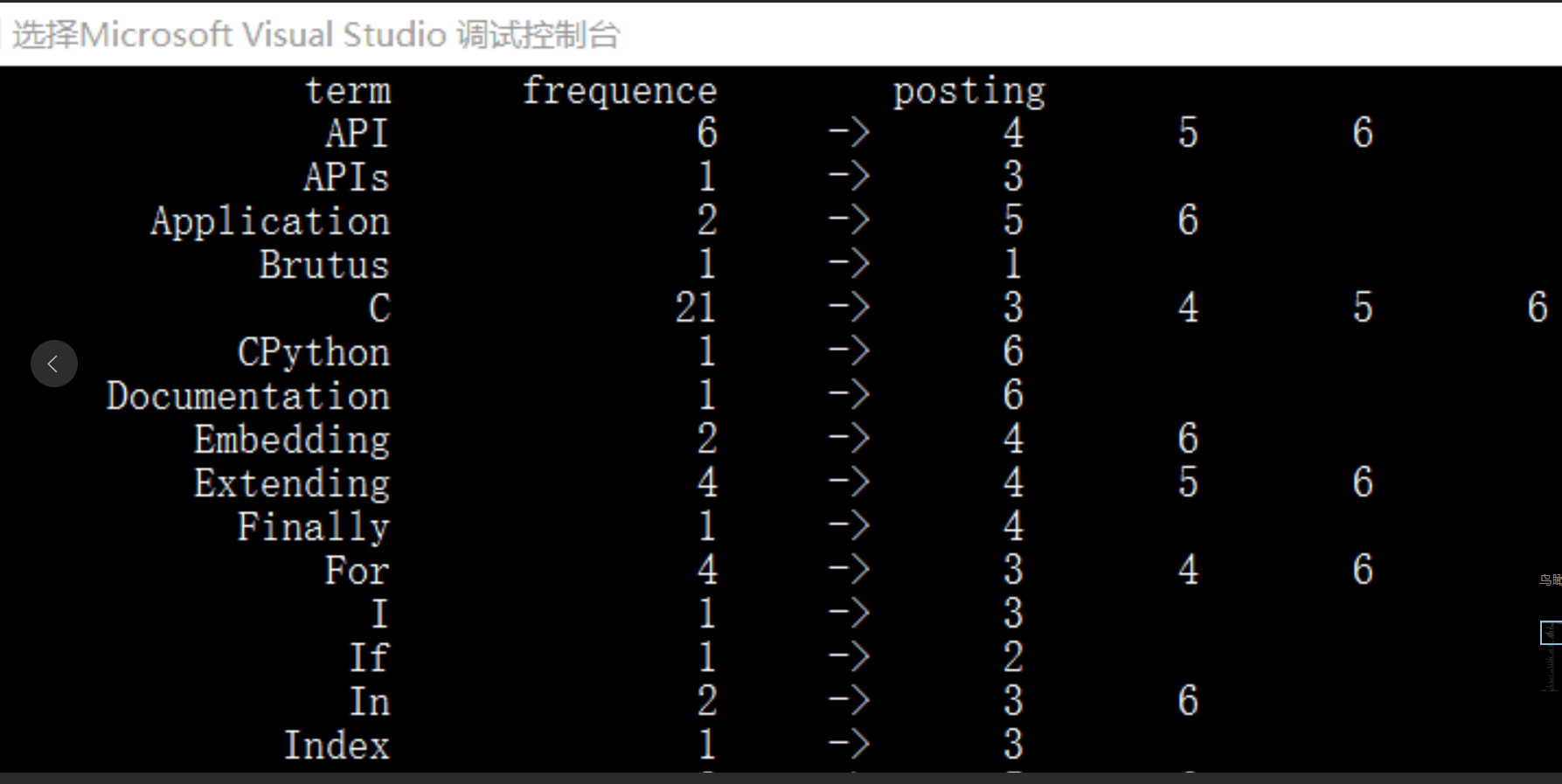
倒排索引的格式大概是下图这样(代码成果图):
每一个词项后面跟着它在文档集中出现的次数,以及出现过的文档的 id 所组成的一个序列。
例如第一条:
就代表API这个词在文档集(六个文件)中出现了六次,这六次分布在文档 4、文档 5 和文档 6。
搜索引擎大致就是这个原理,建立好了索引之后,只需要把你搜索的关键词对应的 posting 求交集然后把对应的文档显示出来就可以了。
数据结构设计 文档(Document) 文档其实在这里就是文件,对于每个文档,都有一个文档名,以及相对应的文档 ID,它们得绑定好,否则会混乱。因此将它们放在一个结构体里面。
1 2 3 4 5 struct Document { string docName; int docID; };
索引项(IndexItem) 同样的,每一个记录的词项、词频和记录表也是绑定的,所以也打包起来。文档 id 的数目不定,又不想自己写链表或者动态数组怕出错,因此采用了 STL(标准模板库)里面的动态数组 vector(向量容器)。
1 2 3 4 5 6 struct IndexItem { string term; int frequence; vector<int > posting; };
索引类(CIndex) 代码应该不难看懂。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class CIndex { vector<IndexItem> indexList; vector<Document> collection; public : CIndex (); CIndex (string p_collection[], int n); void showCollection () void showIndexList () int indexDocument (FILE*fp, int docID) int indexCollection () int sortIndex () int mergeIndex () ~CIndex (); };
大致思路
扫描一篇文档,将这篇文档对应的文档 ID 加入对应词项的 posting
对文档集中每一篇文档重复第一步,获取所有词项及其对应的 posting 加入索引表,此时每个词项的 posting 中只有一个文档 ID,并且有很多重复的词项记录;
排序索引表;
将重复的项的 posting 合并,并且增加词频,删除重复项。
2019-4-4 补充:想到一个新思路——直接按照 ID 从小到大扫描一遍整个文档集,每扫描一个词项,就在词典中查找这个词项,增加词频,然后把现在正在处理的文档的 ID 加入到 posting,最后再排个序即可。
代码实现 有参构造函数 初始化文档集
1 2 3 4 5 6 7 8 9 10 11 12 13 CIndex::CIndex (string p_collection[], int n) { Document nextDoc; for (int i = 0 ; i < n; i++) { nextDoc.docName = p_collection[i]; nextDoc.docID = i+1 ; collection.push_back (nextDoc); } }
索引单篇文档 大致思路是,一个个字符读取进来,如果是字母就一直读完整个单词,并把这个单词作为词项加入表中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 int CIndex::indexDocument (FILE * fp, int docID) char ch; IndexItem indexItem; int num = 0 ; while (!feof (fp)) { do { ch = fgetc (fp); if (feof (fp)) break ; } while (!isalpha (ch)); if (feof (fp)) break ; while (isalpha (ch)) { indexItem.term += ch; ch = fgetc (fp); } indexItem.frequence = 1 ; indexItem.posting.push_back (docID); indexList.push_back (indexItem); num++; indexItem.term="" ; indexItem.posting.clear (); } return num; }
索引文档集 索引文档弄好之后,索引整个文档集不过是加个循环而已
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 int CIndex::indexCollection () int num = 0 ; for (int i = 0 ; i < collection.size (); i++) { FILE* fp = fopen (collection[i].docName.c_str (), "r" ); num+=indexDocument (fp, collection[i].docID); fclose (fp); } return num; }
排序索引表 直接使用<algorithm>头文件里面的sort()函数进行排序,自定义比较函数cmp()
1 2 3 4 5 6 7 8 9 bool cmp (IndexItem a, IndexItem b) return a.term<b.term; } int CIndex::sortIndex () sort (indexList.begin (), indexList.end (), cmp); return 0 ; }
去重 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 int CIndex::mergeIndex () IndexItem item1,item2; sortIndex (); vector<IndexItem>::iterator it_cur=indexList.begin (); vector<IndexItem>::iterator it_next = it_cur + 1 ; vector<int > temp; vector<int >::iterator p1, p2; while (it_cur != indexList.end ()) { if (it_cur+1 !=indexList.end ()) it_next = it_cur + 1 ; else break ; while ((*it_cur).term == (*it_next).term) { sort ((*it_cur).posting.begin (), (*it_cur).posting.end ()); sort ((*it_next).posting.begin (), (*it_next).posting.end ()); p1 = (*it_cur).posting.begin (); p2 = (*it_next).posting.begin (); while (p1 != (*it_cur).posting.end () && p2 != (*it_next).posting.end ()) { if ((*p1) < (*p2)) { temp.push_back (*p1); p1++; } else if ((*p1) > (*p2)) { temp.push_back (*p2); p2++; } else { temp.push_back (*p1); p1++; p2++; } } while (p1 != (*it_cur).posting.end ()) { temp.push_back (*p1); p1++; } while (p2 != (*it_next).posting.end ()) { temp.push_back (*p2); p2++; } temp.erase (unique (temp.begin (), temp.end ()), temp.end ()); (*it_cur).frequence++; (*it_cur).posting.assign (temp.begin (), temp.end ()); indexList.erase (it_next); temp.clear (); if (it_cur + 1 != indexList.end ()) it_next = it_cur + 1 ; else break ; } it_cur++; } return 0 ; }
一开始使用的是普通的 for 循环,但是发现随着元素的删除,循环次数应该改变,因此改成了迭代器加 while 的方式。
迭代器还是个蛮有用的东西,就是一个封装得比较好的指针。
main 测试 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 #include <iostream> #include <algorithm> #include "CIndex.h" #include <string> using namespace std;string fileList[6 ] = { "doc1.txt" , "doc2.txt" , "doc3.txt" , "doc4.txt" , "doc5.txt" , "doc6.txt" }; int main () CIndex in (fileList,6 ) ; in.showCollection (); in.indexCollection (); in.mergeIndex (); in.showIndexList (); return 0 ; }