Scrapy爬虫框架(1)一个简单的可用的爬虫
很久没写爬虫了,又重新开始使用 scrapy,之前学习的内容基本上都忘了,重新复习一遍,发现对它的理解又加深了一些。
本文将初级知识点简单梳理,实现了一个 HelloWorld 级别的 Scrapy 爬虫。
本文适用于 Scrapy 1.6.0,结合了自己的理解,可能理解有错误,欢迎在下面评论区指出。
不包含安装教程。
参考链接
- Scrapy-百度百科
- Python 爬虫-scrapy 介绍及使用
- Scrapy 中文网
- Scrapy 中文网的爬虫实验室
- xpath 教程:
- 学爬虫利器 XPath,看这一篇就够了:这个是结合代码来讲解的
- Python 神技能:六张表 搞定 Xpath 语法:这个是列出语法表的
- VScode Python no module 的解决方法
- Python 中获得当前目录和上级目录
Scrapy 是啥
先看看Scrapy-百度百科的解释:
Scrapy 是一个为爬取网站数据、提取结构性数据而设计的应用程序框架,它可以应用在广泛领域:Scrapy 常应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。通常我们可以很简单的通过 Scrapy 框架实现一个爬虫,抓取指定网站的内容或图片。
它是一个框架,帮你解决写爬虫的过程中遇到的一些问题,简化你写爬虫的过程。对于一些简单的爬虫,你不需要自己来写重复的代码,它将重复的代码都隐藏起来,你只需要写一些与你需要爬取的网站相关的东西就可以了。
例如,爬虫需要发送请求和获取响应,scrapy 有个专门的调度器来帮你解决这个问题,你不需要自己来调度,你只需要使用它的下载器传给你的响应对象 Response 来进行解析即可,解析好的数据你也可以打包成它的一个名为 Item 的类的对象中,更方便地进行处理。方便很多。
Scrapy 的组成
下面这个图片来自于Python 爬虫-scrapy 介绍及使用
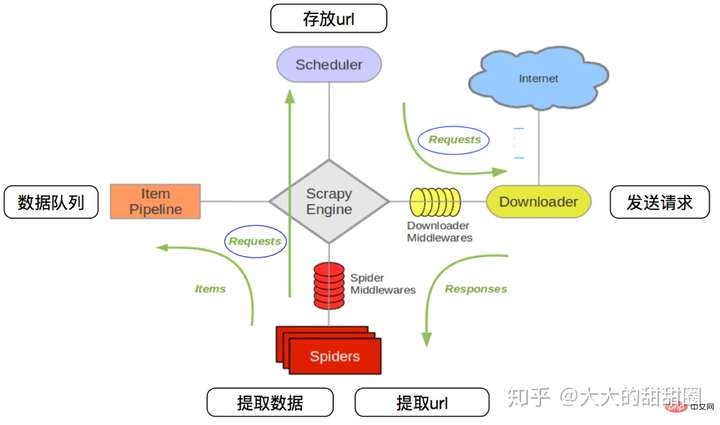
- 调度器(Scheduler)选择合适的时机发送 Request(请求)给下载器;
- 下载器(Downloader)处理 Request(响应),即发送请求并获取响应 Response,将 Response 传给爬虫;
- 爬虫(Spider)主要做两类事情:
- 提取当前 Response 中的数据,打包成 Item(或者是 dict),将它们发送给管道
- 获取 Response 中下一个 Request 的 url(比如你第一个 Response 爬取的是目录页,那么就是获取目录项对应的 url)从而构造下一个 Request,再将这个 Request 发送给调度器
- 管道(Item Pipeline)处理 Item 中的数据
- 中间件(Middleware)分为下载中间件和爬虫中间件,用来在传送 Request 和 Response 过程中做一些额外的处理
- 引擎(Engine)用于将以上模块都连接起来,其他模块都直接与引擎交互,数据等由引擎进行转发
一般我们需要编写的,就是爬虫和管道,也就是解析数据和处理数据。
过程
创建项目
首先在命令行创建项目
1 | $scrapy startproject 项目名称 |
会生成一个以你项目名称命名的文件夹,里面就是你的项目文件
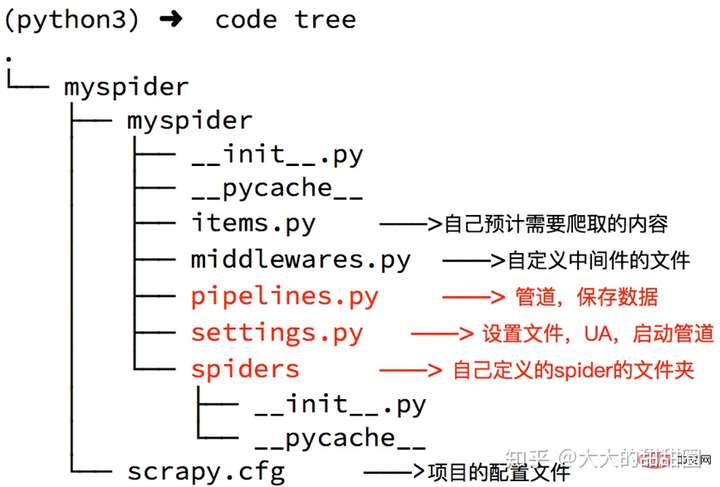
创建爬虫
1 | $scrapy genspider 爬虫名 爬取的域名 |
它的作用是在 spider 目录下按照模板创建一个以你爬虫为名的 py 文件,当然你也可以手动创建,只要你的文件符合 scrapy 的要求就行,最好用命令。
记得先切换到你项目目录。
编写爬虫
我要练习爬取的是Scrapy 中文网提供的爬虫实验室
爬虫命名为 lab,创建好的初始爬虫文件lab.py是这样的
1 | # -*- coding: utf-8 -*- |
- name:爬虫名
- allowed_domains:允许访问的域名,注意是域名,而不是要爬取的 url,别写成http://lab.scrapyd.cn之类的
- start_urls:初始 url
- parse(self,response):解析函数,传入的参数就是 Response 响应,你可以用这个引用来获取网页内容,从而进行处理
运行过程理解
按照我的理解,当启动这个爬虫时:
- scrapy 会将 start_urls 这个列表里面的 url 都生成对应的 Request 发给调度器
- 然后调度器将 Request 通过引擎转发给下载器
- 下载器再将下载好的 Response 发给引擎,引擎调用该爬虫的 parse 方法,将这个 Response 传入作为参数
- 引擎获取 parse 的返回值
- 如果是 Request(即新的请求),就发送给调度器
- 如果是 item 或者 dict,就发送给管道
- 当调度器中没有新的 Request 了,scrapy 停止。
调试解析
1 | $scrapy shell 你要爬取的url |
此处,我要爬取的就是http://lab.scrapyd.cn。
这个命令可以打开交互式调试命令行,如下:
1 | $scrapy shell http://lab.scrapyd.cn |
scrapy 这时已经将 response 给你了,你可以使用这些命令来进行调试。
没错,就是给 parse 函数传的那个 response 参数。
你可以使用:
1 | In[1]:response.text |
来获取得到的 html 字符串,以确定是否成功获取到自己想要的网页。
先去那个网站按 f12 查看一下它的元素:
1 | <div class="col-mb-12 col-8" id="main" role="main"> |
我们需要获取到的,是以下内容:
1 | [{'text': '看官,此页面只为爬虫练习使用,都是残卷,若喜欢可以去找点高清版!', 'tag': ['艺术', '名画']}, |
这个 response 拥有几种解析方法,你可以使用 xpath,也可以用 css。
xpath 教程:
- 学爬虫利器 XPath,看这一篇就够了:这个是结合代码来讲解的
- Python 神技能:六张表 搞定 Xpath 语法:这个是列出语法表的
比如使用 xpath:
1 | In [2]: response.xpath('//div[contains(@class,"quote")]') |
返回的将是 Selector 的列表,Selector 的具体用法也不在本文范围内。
其实response.xpath()只是方便使用,它调用了response.selector.xpath(),也就是说 xpath 和 css 实际上是 Selector 的方法。说这个的原因在于告诉你,对于这个列表里面每一个 Selector,你都可以使用同样的方法来进行解析。
接着你就可以利用这个调试 shell 来调整你的 xpath 字符串或者 css 字符串了。
编写 Item 域
items.py 里面有着你可以用的 item 类,根据你确定需要获取的字段(Field)来给它添加:
1 | # -*- coding: utf-8 -*- |
解析代码
我用的是 css 选择器。
1 | # -*- coding: utf-8 -*- |
开始爬取
1 | $scrapy crawl 需要启动的爬虫名 -o 输出文件名(比如test.json) |
scrapy 会自动将得到的 item 保存到输出文件
解决导入 items 模块的问题
1 | import sys |
Scrapy爬虫框架(1)一个简单的可用的爬虫